Special thanks to my teammate Haoyu Zhang in this project.
1. Introduction
This is the technical report for the Final Project of Carnegie Mellon University Course 15745: Optimizing Compilers. In this project, we practiced some classic optimizer optimization methods and gained hands-on experience. More specially, we realized the techniques discussed in Paper: Aggify: Lifting the Curse of Cursor Loops using Custom Aggregates in DuckDB [1]. This section includes the description of the problem, an overview of our solution and the novel contributions of us.
1.1 Problem Statement
User Defined Functions in databases were considered as performance toxics since its invention by INGRES in the 1980s [2]. Fortunately, one optimization approach on UDFs called Inlining makes a difference. [3] rewrites the procedural logics in UDFs as declarative SQL expressions so that the query optimizer can optimize across the UDF boundary. This technique makes many SQL queries with UDF calls reach near pure SQL performance. [4] comes out later making UDF Inlining applicable to almost all databases that implements the SQL standard. However, this nice technique is not available to UDFs that have cursor loops, which are the programming construct that iterates through the result set of a query, processing each row sequentially.
Aggify [5] is here to help rewrite cursor loops to custom aggregate functions, which are accepted by [3] and [4], completing the last piece of the UDF puzzle. However, Aggify has not been put into production by any system. We would like to be the first to implement it and see if it can help reverse UDF’s bad reputation. Aggify is also useful if the UDF is not inlined. According to its paper, applying Aggify to the cursor loop and then running the UDF sequentially can lead to up to 1000x speedup.
1.2 Our Approach
We choose to target PL/PgSQL UDFs and use DuckDB as the database platform in this project. We choose PL/pgSQL because it is static and the language syntax is relatively conservative, making the data flow analysis process easier. We choose DuckDB because we already have abundant experience with it, and the open-source community of it has been extremely helpful.
To realize Aggify’s idea, we had to first construct a Control Flow Graph (CFG) for the UDF. Then we performed data flow analysis such as reaching definitions and live variable analysis upon the CFG. Based on the analysis results, we followed Aggify to extract the logic for the custom aggregate function and replace the cursor loop with the call to this aggregate. More details about our approach can be found in Section 2. Furthermore, since custom aggregate functions should be defined by C++ in DuckDB. The last step is to generate C++ code for the extracted logic.
1.3 Contributions
We have three main contributions in this project.
- We are the first to correctly implement Aggify in DuckDB or any database system. Combining our work with [3], we allow DuckDB to support all the analytical PL/pgSQL UDFs. During implementation, we modified DuckDB to support Custom Aggregates without Combine() functions.
- We pioneered the compilation path from PL/pgSQL cursor loops to C++ code. This path includes applying compiler optimization passes to CFG of PL/pgSQL and a framework to efficiently add support for expression compilation to a vectorized database system. This contribution is shared by another ongoing project led by Sam Arch@CMU.
- We discovered a fundamental flaw in Aggify’s approach, and proposed an optimized solution. This finding makes Aggify correct in the general case, which is crucial for Aggify to be practically adopted.
2. Compilation of Cursor Loops
DuckDB only allows Custom Aggregates to be defined by a C++ class that implements certain methods. There are several steps for us to correctly implement generate the correct C++ code. We will walk them through in logical order in this section.
2.1 Construction of CFG for PL/pgSQL
To effectively rewrite cursor loops in PL/pgSQL functions, we must first represent the program using an intermediate representation (IR). This process involves two critical sub-routines: parsing the input SQL functions into an intermediate representation (IR) and subsequently constructing a Control Flow Graph (CFG) from this IR:
- We first parse the input SQL functions into an AST. Here, we chose to use JSON for our AST because it’s easy to generate directly from parsing.
- With the JSON-formatted ASTs, we are able to construct the CFG. This is done by a dedicated compiler which traverses the AST and handles different types of nodes (e.g., assignments, if statements, while loops).
Now, we will discuss there two sub-routines in details.
2.1.1 Parsing
The initial phase involves parsing the input SQL functions. The chosen intermediate representation for this task is JSON, owing to its intuitive structure. The result of this parsing process is a set of Abstract Syntax Trees (ASTs) corresponding to the input SQL functions. These ASTs serve as a structured and detailed representation of the syntactic and structural elements of the PL/pgSQL code.
2.1.2 CFG Construction
Once the ASTs are obtained in JSON format, the next step is the construction of the Control Flow Graph (CFG). This process is handled by a specialized compiler designed to traverse the AST and manage various node types found in PL/pgSQL, including assignments, conditional statements (if statements), and loops (while and for loops).
The CFG construction is a complex but crucial process, involving several key steps:
- Basic Block Creation: The compiler starts by creating basic blocks. A basic block is a sequence of consecutive statements or expressions where control enters at the beginning and leaves at the end without halt or possibility of branching except at the end. Appendix item A.1 shows the result of this step.
- Handling Different Statements: The compiler identifies different types of statements in the AST – such as assignments, returns, conditional statements, and loops. Each type of statement is processed to reflect how control flows through the program.
- Assignment and Return Statements: These are straightforward, involving direct mapping from the AST to the CFG.
- Conditional Statements (If, ElseIf, Else): The compiler creates branches in the CFG to represent the flow of control between different blocks based on conditions.
- Loops (While, For, etc.): Loop constructs are handled by creating blocks that represent the start and end of the loop, along with the condition check.
-
Utilizing Continuations: A key aspect of CFG construction in this context is the use of continuations. Continuations represent the next step of computation and are crucial for representing complex control flows like nested loops and conditional branches.
The continuation we are using is represented as a struct in our code:
1 2 3 4 5 6 7 8 9 10 11
struct Continuations { Continuations(BasicBlock *fallthrough, BasicBlock *loopHeader, BasicBlock *loopExit, BasicBlock *functionExit) : fallthrough(fallthrough), loopHeader(loopHeader), loopExit(loopExit), functionExit(functionExit) {} BasicBlock *fallthrough; BasicBlock *loopHeader; BasicBlock *loopExit; BasicBlock *functionExit; };
It is used to manage where to transfer control at different points in the program’s execution, especially in more complex control structures like loops and conditional statements. In essence, this
Continuationsstruct provides a way to encapsulate the necessary information for directing the flow of control in various program constructs. - Merging Basic Blocks: In our implementation, when creating the CFG, we are creating a new basic block for every instructions. So in this clean-up routine, we merge basic blocks legally to achieve a maximum number of instructions in each block. Please refer to the appendix to see the difference before and after merging. Appendix item A.2 shows the result of this step.
2.2 Analysis and Rewrite on the CFG
Given a cursor loop (Q, Δ) our goal is to construct a C++ Custom Aggregate that is equivalent to the original cursor loop, Δ . To complete the transform, we mainly follow the exact Aggify approach that involves data flow analysis and CFG modification.
There are three required methods for a Custom Aggregate to be registered within DuckDB:
initialize: Constructs theStatein raw memory.update: Accumulate the arguments into the correspondingState.finalize: Convert aStateinto a final value.
The first method can be easily handled in our transpiler, so we do not bother constructing it in PL/pgSQL. We will focus on the discussion of the remaining three methods.
We will use the SQL example below to explain the rewrite process. This query finds out the supplier who is selling a given part with minimum cost.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
/* Code Example 1: Cursor Loop Rewrite Target */
/* Postgres version of UDF */
CREATE OR REPLACE FUNCTION MinCostSupp(pk bigint)
RETURNS char(25)
STABLE AS
$$
DECLARE
key bigint := pk;
fetchedCost decimal(15, 2);
fetchedName char(25);
minCost decimal(25, 2) := 100000;
val char(25);
BEGIN
FOR fetchedCost, fetchedName IN (SELECT PS_SUPPLYCOST, S_NAME
FROM partsupp,
supplier
WHERE PS_PARTKEY = key
AND PS_SUPPKEY = S_SUPPKEY)
LOOP
IF fetchedCost < minCost THEN
minCost := fetchedCost;
val := fetchedName;
END IF;
END LOOP;
RETURN val;
END;
$$ LANGUAGE plpgsql;
/* UDF call */
EXPLAIN ANALYZE
SELECT P_PARTKEY, MinCostSupp(P_PARTKEY)
FROM part;
Please refer to the appendix section for the complete rewritten version of the above cursor-loop query.
Fields
The first step of our rewrite is to identify the minimal set of fields that are needed in our custom aggregate. This is done by performing liveness analysis to get $V_{local}$, the set of variables that are local to the loop body; and by analyzing the use-def chain to obtain $V_{fetch}$, the set of variables assigned in the FETCH statement, as well as $V{\Delta}$, all variables referenced in the loop body Δ. The set of variables $V_F$ defined as fields of the custom aggregate is given by the equation:
\[V_F = V_{\Delta} − (V_{fetch} ∪ V_{local}) ∪ {isInitialized}\]For Code Example 1 shown above, after applying the analyses, we have:
\[\begin{aligned} V_{\Delta}& = \{key, val, minCost, fetchedCost, fetchedName\} \\ V_{fetch}& = \{fetchedCost, fetchedName\} \\ V_{local}& = \{\} \\ V_{F}& = \{val, minCost\} \end{aligned}\]Meaning val and minCost are the fields necessary to put into the generated custom aggregate.
Initialize()
This initialization process will only set the aggregate’s is_initialized state to false. The initialization of other parameters, which can only be determined at runtime, will be deferred until the update() function is called, i.e., when the actual accumulation function is invoked.
Update()
This method is the core of custom aggregates, which encapsulate the critical accumulation across table rows. We need to construct its parameters and method body by doing more data flow analyses.
Parameters. Let $P_{accum}$ denote the set of parameters which is identified as the set of variables that are used inside the loop body and have at least one reaching definition outside the loop. The set of candidate variables is computed using the results of reaching definitions analysis. More formally, let 𝑉𝑢𝑠𝑒 be the set of all variables used inside the loop body. For each variable 𝑣 ∈ 𝑉𝑢𝑠𝑒 , let $U_{CL}(v)$ be the set of all uses of 𝑣 inside the cursor loop CL. Now, for each use 𝑢 ∈ $U_{CL}(v)$, let RD(𝑢) be the set of all definitions of 𝑣 that reach the use 𝑢. We define a function 𝑅(𝑣) as follows. [2]
\[R(v) = \begin{cases} 1, & \text{if } \exists d \in RD(u) \mid d \text{ is not in the loop.} \\ 0, & \text{otherwise}.\end{cases}\]Then, we obtain the $P_{accmu}$ set of parameters for update() as follows:
Method Body. There are two blocks of code that form the definition of update() – field initializations and the loop body block. The fields need to be initialized are given by this simple equation:
Here’s a piece of sample code for the field initializations block in our implementation:
1
2
3
4
if (!state.is_initialized) {
state.min_cost = pmin_cost;
state.is_initialized = true;
}
As discussed in the previous section, we rely on the boolean state is_initialized , which is set to false statically, to initialize the runtime arguments. When the update() method of a custom aggregate is called the first time, the corresponding states will be assigned by runtime-provided values. Future calls to update() will not trigger the initializations again.
Again, for the same example above, we have:
\[\begin{aligned} P_{accum}& = \{minCost, fetchedCost, fetchedName\} \\ V_{init}& = \{minCost\} \\ \end{aligned}\]For the loop body block, we replace it with the equivalent accumulation semantics:
1
2
3
4
if (current_cost < state.min_cost) {
state.min_cost = current_cost;
state.supp_name = current_name;
}
Finalize()
This method simply returns the aggregate’s internal state that represents the anticipated query result. Here, the state being returning is the supplier’s name.
1
2
3
std:string finalize() {
return state.supp_name;
}
The result of the custom aggregate construction is compiled as a dynamic library and linked to DuckDB at runtime. This case, any future queries can use it as other built-in ones.
Modify original UDF CFG to use the Custom Aggregate
The final step in our cursor loop rewriting process involves utilizing a User-Defined Function (UDF) to encapsulate the custom aggregate we have created. This UDF will be supplied with the previously mentioned variable $V_F$ as local parameters. Subsequently, the aggregate is invoked with the expected parameters within this UDF context.
Once completed, this UDF will be integrated into DuckDB. This integration allows us to utilize the rewritten aggregate by invoking its corresponding wrapper UDF. The complete code can be found in appendix item A.4.
2.3 Compilation of the CFG to C++
This section will illustrate the loop body CFG compilation as mentioned in section 2.2 in details. Compilation can be classified as procedural code compilation and SQL statement compilation. Information entailed by the CFG structure at the basic block level is considered as procedural code, and all the instructions within basic blocks are SQL statements. We take different approaches for both cases.
2.3.1 Procedural Construct Compilation
Once the UDF is expressed as a control flow graph (basic blocks with terminating branch instructions), the translation to C++ becomes straightforward.
1
2
3
4
5
6
7
8
9
10
11
entry:
jmp L0
L0:
INT x = y;
jmp L1;
L1:
INT z = y;
br (z > 0) L2, L0;
L2:
jmp exit
exit:
For each basic block, emit a corresponding label in the C++ program. Next, for each instruction in the basic block, use the SQL Statement Compilation approach to emit a corresponding C++ statement. Finally, for the terminating branch instruction at the end of each basic block, emit a corresponding goto (or conditional goto) in the C++ program. After this process, we have generated a C++ program that is equivalent to the CFG representation.
2.3.2 SQL Statement Compilation
While there is corresponding C++ constructs for every procedural construct in PL/pgSQL, to compile the SQL statements that uses built-in SQL operators or expressions, we need to call the corresponding DuckDB implementation of such logic.
1
2
3
4
5
INT a;
LONG b;
DOUBLE c;
...
c := a + b
Take the above assignment instruction c := a + b as an example, essentially, we want our final C++ result to look like c = duckdb::AddLongDouble(a, b). The trick we used to quickly transform DuckDB to be query compilation friendly is to add code generation useful information to the generated Logical Plan. Logical Plans are tree structures DuckDB constructs as the result of parsing and binding the SQL queries. For the example, the SQL query is SELECT a + b from tmp_table. (We use tmp_table to provide type information of a and b to DuckDB.)
We modified the DuckDB Binder, so when the DuckDB’s vectorized operator is bound to the each computation node in the logical plan, we provide more information related to this vectorized operator. Metadata we insert include the function name of the corresponding scalar function, template instantiation if the scalar function uses, etc.
Finally, we backtrack through the Logical Plan and use the inserted metadata to generate C++ code. These C++ codes invoke internal DuckDB functions so they are guaranteed to give the same result as if DuckDB executes it. This process is also known as the Futamura projections **[7], or partial evaluation.**
3. Fix to Aggify’s Design Flaw
Surprisingly, when trying to reproduce Aggify’s experiment result, we found a major design flaw. Take one of the Aggify proposed test cases in Figure 1(a) as an example; the result of applying Aggify to this cursor loop is shown in Figure 1(b). custom_count is the custom aggregation function that behaves the same as native count except that it lacks a Combine() method, so it cannot run in parallel. As expected, Aggify can generate the correct result for this test case in the context. However, after changing the initial value of val to a non-zero number, it is obvious that Aggify’s transformation is incorrect. For example, if the cursor (pink) query returns empty, by running the cursor loop normally and iteratively, the value of val should be unchanged and the UDF should return 100 (shown in Figure 1(c)). However, the custom aggregate will overwrite val to be 0 in (shown in Figure 1(d)), which produces a result that is inconsistent with the original UDF containing a cursor loop.

Figure 1. (b) is the result of Aggify for (a); (d) is the result of Aggify for (c)
We now propose a simple fix to this issue. Since the main problem happens when the cursor query returns empty, it is necessary to insert a precondition before the custom aggregate to ensure the cursor query always returns something. Therefore, the correct transformation for (c) in Figure 1 is shown in Figure 2. This fix introduces a new query that performs duplicate work.
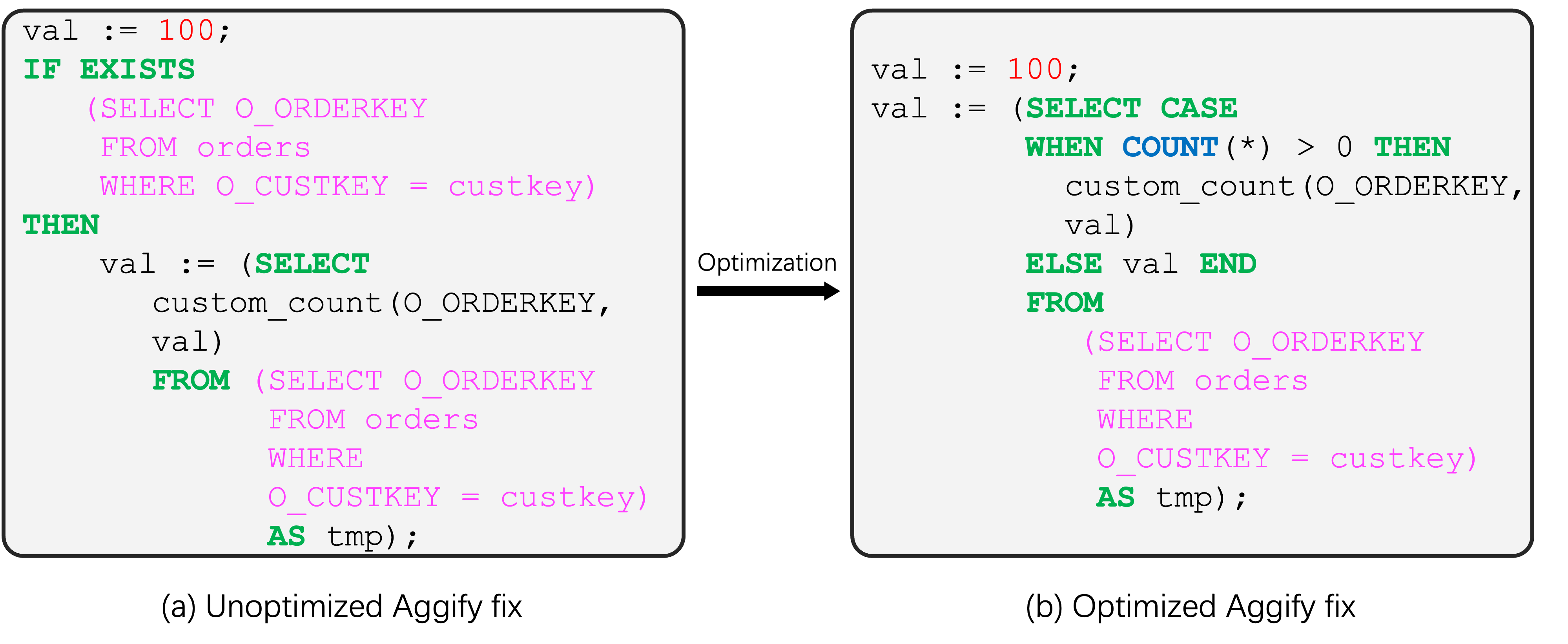
Figure 2. Examples of unoptimized fix to Aggify v.s. optimized fix to Aggify
It is hoped that Common Subexpression Elimination, which is a query optimization technique DuckDB use to find common subqueries and run it only once, can detect it. However, later experiment suggests otherwise. After testing with result-equivalent but syntactically different SQL expression, the best way to implement the correction to Aggify is to use a CASE WHEN statement in replacement of IF EXISTS. Figure2.(b) shows the optimization of (a) in Figure 2, where one less table scan is needed. Appendix item A.5 shows a complete example of the correction described in this section.
4. Experiments
To be able to run the test cases described in the paper, we have to modify DuckDB so that it can run Custom Aggregates without Combine() functions.
4.1 Preparation of DuckDB for the Experiment
Combine() methods of custom aggregation functions in DBMSs (database management systems) define the logic to combine the result of aggregating two groups into one. If an aggregation function has a Combine() function then the execution engine can partition a large group into small ones, apply the aggregate to each partition in parallel, and finally combine all the results. Automatically inferring the Combine() function from a cursor loop is out of scope for the Aggify paper (and we suspect is not possible in the general case). Another challenge is that DuckDB forces the user to provide a Combine() function. Therefore, to implement Aggify in DuckDB, we had to modify the query execution to run custom aggregates in a single-threaded fashion, alleviating the need to provide a Combine() function.
4.2 Setup
Our experiment uses the TPC-H dataset with a scale factor 10 running on a MacBook with Apple M1 Pro chip and 32GB of RAM. For each of the tests, we ran it ten times and compute the average.
4.3 Results and Evaluation
We first compare the performance of the original Aggify (without our fix) with that of built-in aggregates (which represent the best possible performance).
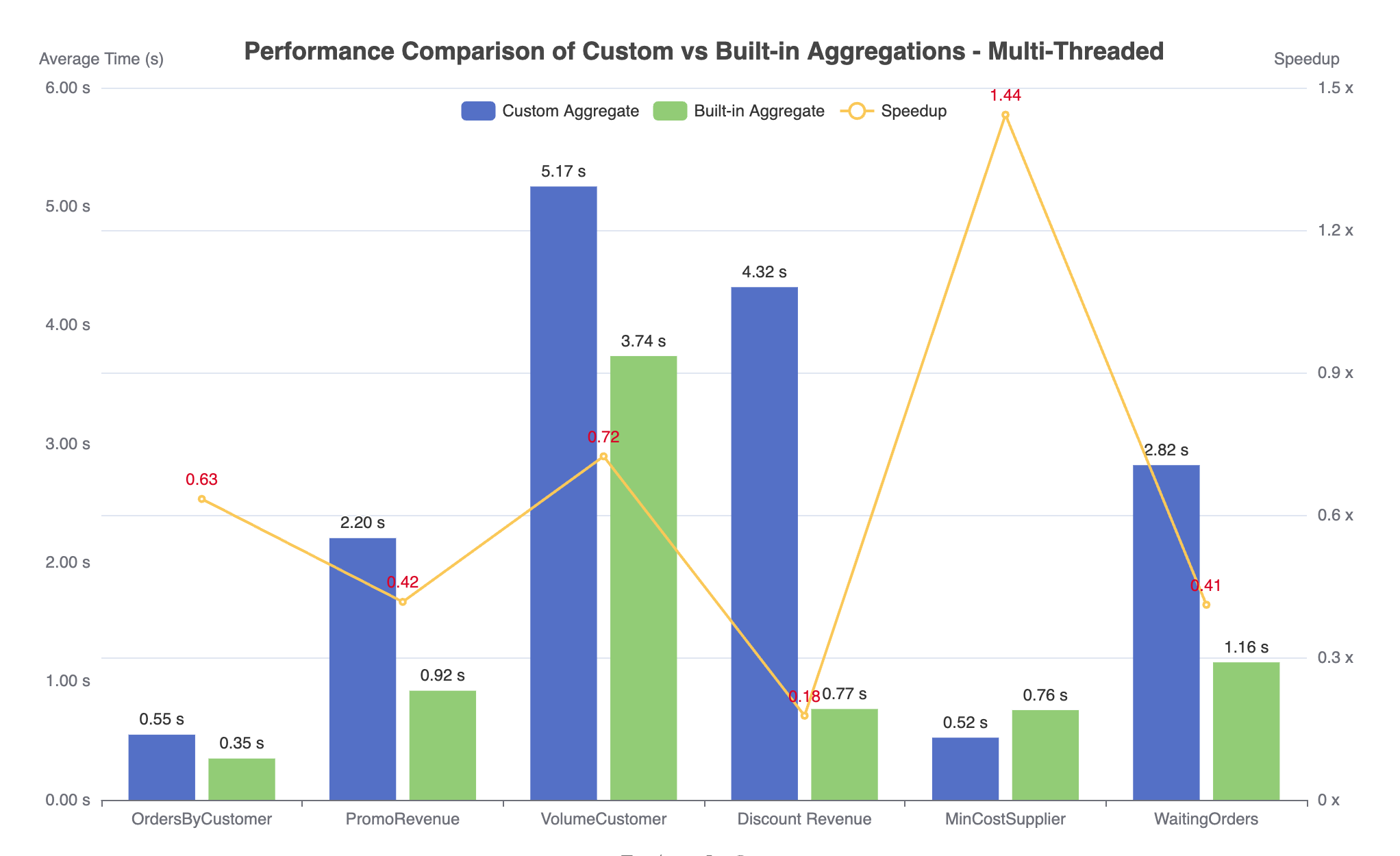
Figure 3. Performance comparison of Aggify using custom aggregate (workload1) or built-in aggregate (workload2), with multi-threading enabled.
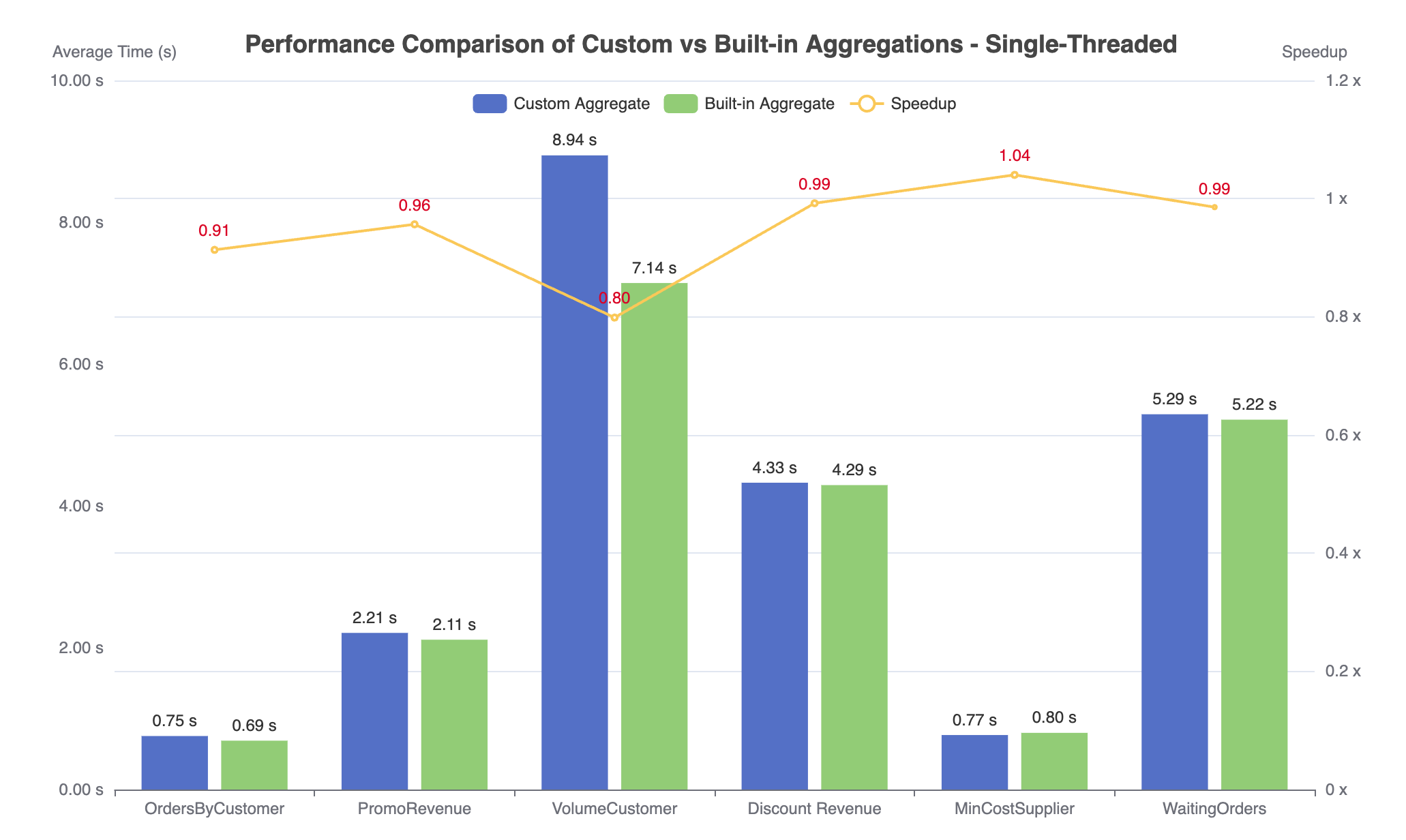
Figure 4. Performance comparison of Aggify using custom aggregate (workload1) or built-in aggregate (workload2), with only one thread used.
As expected, custom aggregates generally do not perform as well as built-in ones, up to 0.18 times slower for workload DiscountRevenue in Figure 3. The performance gap can be explained by the lack of parallelism. Since Aggify generates custom aggregate functions without a Combine() function, they are forced to run sequentially compared to built-in aggregates which can fully exploit the available parallelism. To further support this argument, we make DuckDB run the two workloads again single-threaded. In this case, Aggify shows a similar performance with the built-in aggregate, as shown in Figure 4. An interesting, future research direction would be to use more sophisticated program analysis techniques to infer the Combine() function for cursor loops.
After applying the fix to Aggify we outlined above, the performance of Aggify gets worse. Because the fix basically runs the same subquery twice, the time of it doubles. By optimizing if-exist statement with case-when, we are able to narrow this gap (Figure 5). For some workloads like PromoRevenue and DiscountRevenue, the correction is actually faster than original Aggify. This is because the condition of case-when filters many groups, so the time-consuming custom-aggregate does not need to be invoked.
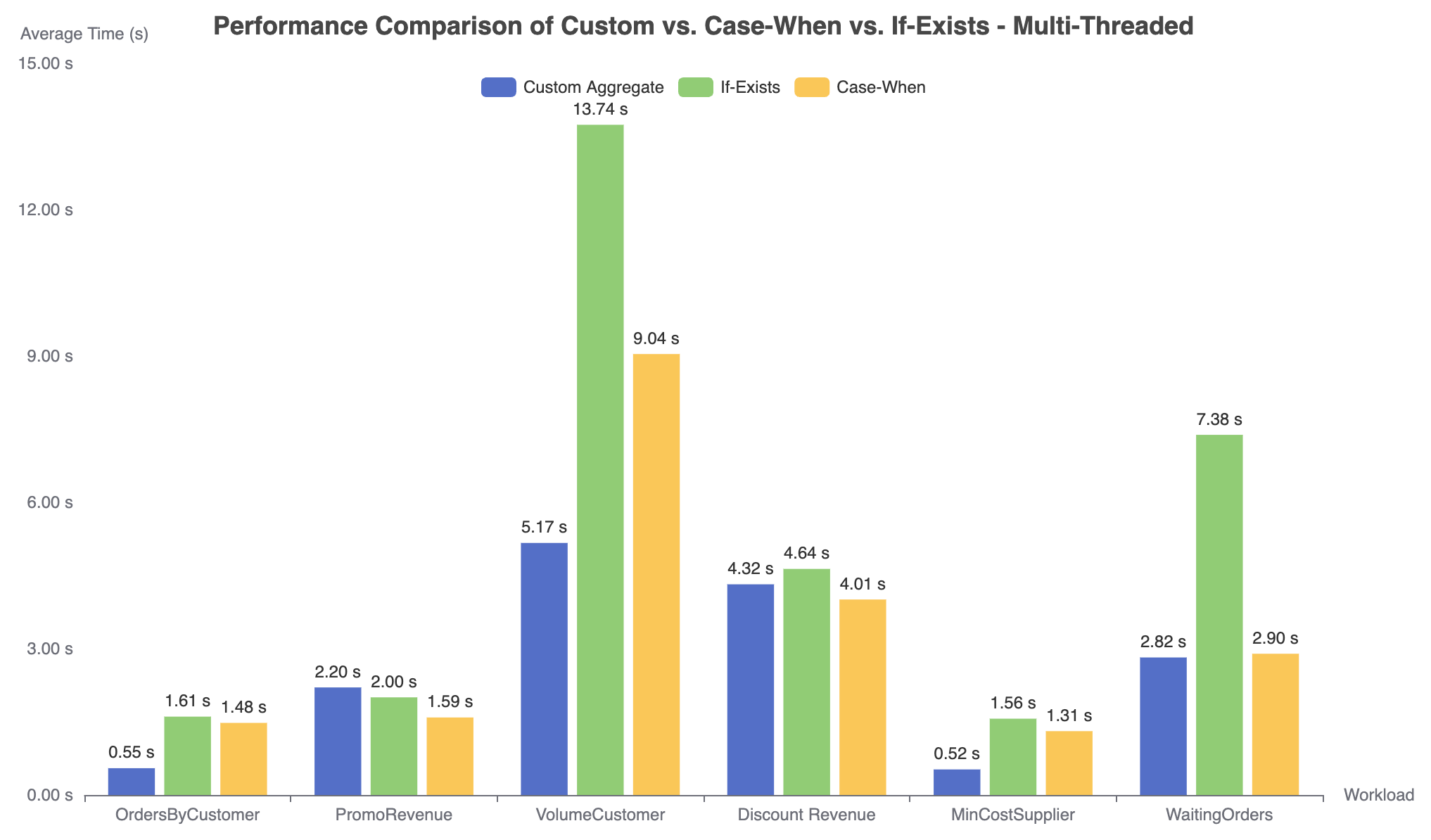
Figure 5. Performance comparison of the original Aggify with two of its fixes
5. Conclusion
In this project, we implemented Aggify from end to end in DuckDB. We also addressed a bug in Aggify. Future efforts in this topic can focus on applying well-known loop optimization techniques like Loop Invariant Code Motion to the cursor loop. It is also interesting to see SQL specific optimizations for loops.
6. References
[1] M. Raasveldt and H. Mühleisen, “DuckDB: an Embeddable Analytical Database,” in Proceedings of the 2019 International Conference on Management of Data, Amsterdam Netherlands: ACM, Jun. 2019, pp. 1981–1984. doi: 10.1145/3299869.3320212.
[2] J. Ong et al. Implementation of data abstraction in the relational database system ingres. SIGMOD Record, 1983.
[3] S. Gupta, S. Purandare, and K. Ramachandra, “Aggify: Lifting the Curse of Cursor Loops using Custom Aggregates,” in Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data, Portland OR USA: ACM, Jun. 2020, pp. 559–573. doi: 10.1145/3318464.3389736.
[4] K. Ramachandra, K. Park, K. V. Emani, A. Halverson, C. Galindo-Legaria, and C. Cunningham, “Froid: optimization of imperative programs in a relational database,” Proc. VLDB Endow., vol. 11, no. 4, pp. 432–444, Dec. 2017, doi: 10.1145/3186728.3164140.
[5] D. Hirn and T. Grust, “One WITH RECURSIVE is Worth Many GOTOs,” in Proceedings of the 2021 International Conference on Management of Data, Virtual Event China: ACM, Jun. 2021, pp. 723–735. doi: 10.1145/3448016.3457272.
[6] M. Sichert and T. Neumann, “User-defined operators: efficiently integrating custom algorithms into modern databases,” Proc. VLDB Endow., vol. 15, no. 5, pp. 1119–1131, Jan. 2022, doi: 10.14778/3510397.3510408.
[7] Y. Futamura, “Partial Evaluation of Computation Process — An approach to a Compiler-Compiler”, Transactions of the Institute of Electronics and Communications Engineers of Japan, 54-C: 721–728, 1971
7. Appendix
A.1 - CFG Before Basic Block Merging

A.2 - CFG After Basic Block Merging
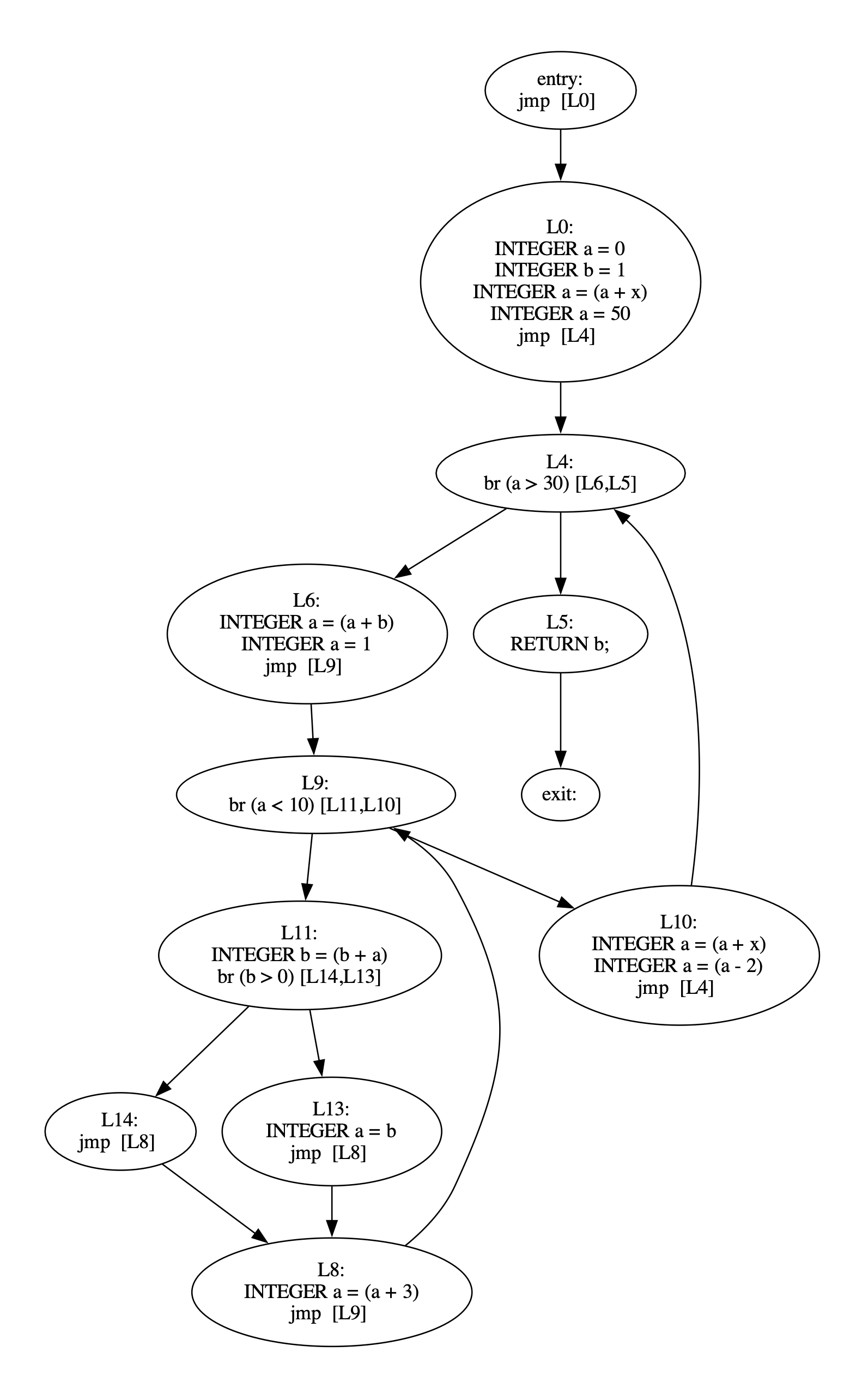
A.3 - Cursor Loop Query Before Rewriting
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
/* Postgres version of UDF */
CREATE OR REPLACE FUNCTION MinCostSupp(pk bigint)
RETURNS char(25)
STABLE AS
$$
DECLARE
key bigint := pk;
fetchedCost decimal(15, 2);
fetchedName char(25);
minCost decimal(25, 2) := 100000;
val char(25);
BEGIN
FOR fetchedCost, fetchedName IN (SELECT PS_SUPPLYCOST, S_NAME
FROM partsupp,
supplier
WHERE PS_PARTKEY = key
AND PS_SUPPKEY = S_SUPPKEY)
LOOP
IF fetchedCost < minCost THEN
minCost := fetchedCost;
val := fetchedName;
END IF;
END LOOP;
RETURN val;
END;
$$ LANGUAGE plpgsql;
/* UDF call */
EXPLAIN ANALYZE
SELECT P_PARTKEY, MinCostSupp(P_PARTKEY)
FROM part;
A.4 - Cursor Loop Query After Rewriting
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
-- Internal states
CREATE TYPE min_cost_state AS (
min_cost DECIMAL(15, 2),
supp_name CHAR(25),
is_initialized BOOLEAN
);
-- Update function
CREATE OR REPLACE FUNCTION f_update(
current_cost DECIMAL(15, 2),
current_name CHAR(25),
pmin_cost DECIMAL(15, 2),
)
RETURNS min_cost_state
LANGUAGE plpgsql AS $$
BEGIN
IF NOT state.is_initialized THEN
state.min_cost := pmin_cost;
state.is_initialized := true;
END IF;
IF current_cost < state.min_cost THEN
state.min_cost := current_cost;
state.supp_name := current_name;
END IF;
RETURN state;
END;
$$;
-- Finalize function
CREATE OR REPLACE FUNCTION f_finalize()
RETURNS CHAR(25)
LANGUAGE plpgsql AS $$
BEGIN
RETURN state.supp_name;
END;
$$;
-- Aggregate
CREATE AGGREGATE MinCostSuppAggregate ()
(
BASETYPE = DECIMAL(15, 2),
STYPE = min_cost_state,
SFUNC = f_update,
FINALFUNC = f_finalize
stype.supp_name = '',
stype.is_initialized = false
);
-- UDF, Wrapper
CREATE OR REPLACE FUNCTION MinCostSuppWithCustomAgg(pk BIGINT)
RETURNS CHAR(25)
LANGUAGE plpgsql AS $$
DECLARE
key bigint := pk;
val CHAR(25);
pmin_cost DECIMAL(25, 2) := 100000;
BEGIN
SELECT MinCostSuppAggregate(PS_SUPPLYCOST, S_NAME, pmin_cost)
FROM (SELECT PS_SUPPLYCOST, S_NAME
FROM partsupp,
supplier
WHERE PS_PARTKEY = key
AND PS_SUPPKEY = S_SUPPKEY) S
INTO val;
RETURN val;
END;
$$;
-- UDF Call
SELECT P_PARTKEY, MinCostSuppWithCustomAgg(P_PARTKEY)
FROM part;
A.5 - Cursor Loop Query After Rewriting and Correction
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
-- Type your code here, or load an example.
CREATE OR REPLACE FUNCTION MinCostSuppWithCustomAgg(pk BIGINT)
RETURNS CHAR(25)
LANGUAGE plpgsql AS $$
DECLARE
key bigint := pk;
val CHAR(25);
pmin_cost DECIMAL(25, 2) := 100000;
BEGIN
if exists (SELECT PS_SUPPLYCOST, S_NAME
FROM partsupp,
supplier
WHERE PS_PARTKEY = key
AND PS_SUPPKEY = S_SUPPKEY) then
val := (SELECT MinCostSuppAggregate(PS_SUPPLYCOST, S_NAME, pmin_cost)
FROM (SELECT PS_SUPPLYCOST, S_NAME
FROM partsupp,
supplier
WHERE PS_PARTKEY = key
AND PS_SUPPKEY = S_SUPPKEY) tmp);
end if;
RETURN val;
END;
$$;
-- Type your code here, or load an example.
CREATE OR REPLACE FUNCTION MinCostSuppWithCustomAgg(pk BIGINT)
RETURNS CHAR(25)
LANGUAGE plpgsql AS $$
DECLARE
key bigint := pk;
val CHAR(25);
pmin_cost DECIMAL(25, 2) := 100000;
BEGIN
val := (SELECT case when count(*) > 0 then
MinCostSuppAggregate(PS_SUPPLYCOST, S_NAME, pmin_cost) else val end
FROM (SELECT PS_SUPPLYCOST, S_NAME
FROM partsupp,
supplier
WHERE PS_PARTKEY = key
AND PS_SUPPKEY = S_SUPPKEY) tmp);
RETURN val;
END;
$$;
-- Q:
SELECT P_PARTKEY, MinCostSuppWithCustomAgg(P_PARTKEY)
FROM part;